
Dzisiaj chciałbym zwrócić Waszą uwagę na pilnowanie typów danych w MS SQLu (i w innych silnikach bazodanowych pewnie też). Czasami przez nieuwagę możemy nieźle namieszać na bazie i nawet początkowo o tym nie wiedzieć.
Załóżmy, że w bazie mamy takie 3 tabele:
Products (z indeksem klastrowym na ID):
CREATE TABLE [dbo].[Products](
[ID] [varchar](7) NOT NULL,
[Name] [nvarchar](100) NOT NULL,
[Barcode] [varchar](10) NULL
) ON [PRIMARY]Stores (z indeksem klastrowym na ID):
CREATE TABLE [dbo].[Stores](
[ID] [int] NOT NULL,
[Name] [nvarchar](100) NOT NULL
) ON [PRIMARY]StoresProducts (z indeksem klastrowym na ProductID i StoreID):
CREATE TABLE [dbo].[StoresProducts](
[ProductID] [int] NOT NULL,
[StoreID] [int] NOT NULL
) ON [PRIMARY]Struktura bardzo prosta. Kolekcja produktów, sklepów i tabelka łącząca sklepy z produktami.
Niektórzy z Was pewnie już zwrócili uwagę na kolumnę ID w tabeli Products oraz ProductID w StoresProducts. Mamy tutaj inne typy danych, choć jak można by się domyśleć, wartości te są ze sobą powiązane. Skąd pomysł na varchar(7) dla id produktu to trochę inny temat (np. autor założył, że id będzie posiadało zera wiodące), ale taki twór może się zdarzyć, więc warto się tym zainteresować.
Skoro mamy już bazę, to pora na zapytanie :).
Powiedzmy, że potrzebujemy pobrać listę wszystkich sklepów, w których sprzedawany jest dany produkt. Jeżeli dany produkt nie jest sprzedawany w jakimś sklepie, to i tak musimy go mieć na liście, ale z NULLami.
Zapytanie mogłoby wyglądać tak (* w zapytaniu umieszczam celowo, aby nie komplikować zapisu na blogu):
SELECT * FROM Stores s
LEFT JOIN StoresProducts sp ON s.ID = sp.StoreID AND sp.[ProductID] = 102392
LEFT JOIN [dbo].[Products] p ON p.ID = sp.ProductIDZapytanie wygląda dobrze i nawet działa:
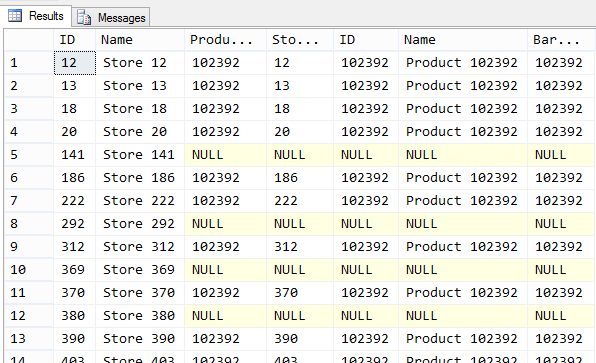
Ale jak zerkniemy na plan wykonania:

to zobaczymy, że mamy konwersję typu kolumny ProductID.
Co można z tym zrobić? Np. rzecz, która z początku wydaje się bezsensowna – stworzyć tabelę mapującą id typu varchar(7) na int:
CREATE TABLE [dbo].[ProductIdTranslations](
[ProductID] [int] NOT NULL,
[ProductIDChar] [varchar](7) NOT NULL
) ON [PRIMARY]Z taką tabelą zapytanie wyglądać będzie tak:
SELECT * FROM Stores s
LEFT JOIN (
SELECT sp2.[ProductID], sp2.[StoreID],pt.[ProductIDChar] FROM [dbo].[StoresProducts] sp2
INNER JOIN [dbo].[ProductIdTranslations] pt ON sp2.[ProductID] = pt.[ProductIDChar] AND pt.[ProductID] = 102392
) sp ON s.ID = sp.StoreID
LEFT JOIN [dbo].[Products] p ON p.ID = sp.[ProductIDChar]O wiele bardziej skomplikowane, ale zobaczmy statystyki:

Jak widać jest szybciej i mamy mniej odczytów.
Dla porównania jeszcze taka wersja:
SELECT * FROM Stores s
LEFT JOIN StoresProducts sp ON s.ID = sp.StoreID AND sp.[ProductID] = 102392
LEFT JOIN [dbo].[Products] p ON CAST(p.ID as INT) = sp.ProductID
Opisany przypadek może wydawać się hardcore’owy, ale taki jest łatwiej zapamiętać :).
Trzeba pamiętać, że taki problem możemy mieć również przy prostszych zapytaniach:
DECLARE @barCodeInt INT
SET @barCodeInt = 32806
SELECT * FROM [dbo].[Products]
WHERE Barcode = @barCodeInt
----------------------------------
DECLARE @barCodeVarchar varchar(10)
SET @barCodeVarchar = '32806'
SELECT * FROM [dbo].[Products]
WHERE Barcode = @barCodeVarcharZapytanie bardzo proste – pobieramy produkt na podstawie podanego barcodu, ale z jakiegoś powodu w jednym przypadku zmienna przechowująca barcode posiada typ INT.
Jak wyglądać będzie wykonanie takich zapytań?

Różnicy nie widać, ale jak założymy na kolumnie Barcode indeks nieklastrowy, to otrzymamy takie wyniki:

Jak widać, jest o co walczyć.
A dlaczego tak się dzieje, widać poniżej:
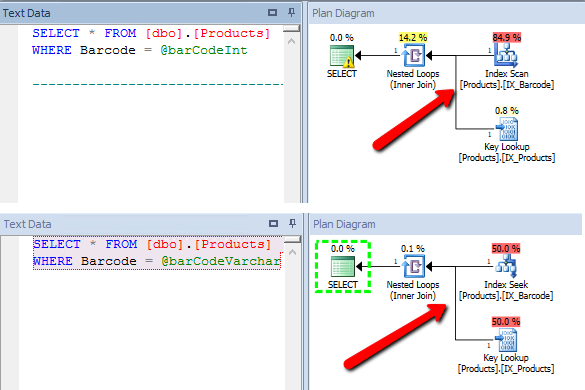
Jak widać, w sytuacji złego typu, optymalizator wykonał pełny skan indeksu. I na tym straciliśmy.
Dlatego pamiętajcie, żeby sprawdzać plany wykonania nawet najprostszych zapytań i walczyć nawet o milisekundy.







17 comments
Te statystyki czasu to z jakiego toola?
Paweł
http://www.sqlsentry.net/plan-explorer/sql-server-query-view.asp
“Dlatego pamiętajcie, żeby sprawdzać plany wykonania nawet najprostszych zapytań i walczyć nawet o milisekundy.”
To mi się podoba 🙂
Tak, również polecam tego toola.
Generalnie klucze klastrowane jako varchar to masakra, ponieważ bardzo ciężko będzie nam zachować rosnącą monotoniczność klucza, właściwie należy tego pilnować albo zaimplementować własny mechanizm. Są przypadki kiedy klucz monotoniczny nie jest tym czego chcemy (dużo stron aby zmniejszyć page lock contention) ale w 99.99% przypadków chcemy mieć monotoniczne rosnący klucz.
zgadzam się – tutaj chciałem bardziej opisać problem różnych typów danych. a że ludzka fantazja nie zna granic to varchar w indeksie się zdarzyć może 🙂
“Dlatego pamiętajcie, żeby sprawdzać plany wykonania nawet najprostszych zapytań i walczyć nawet o milisekundy.” – kompletnie sie z tym nie zgadzam – “bawiac” sie w ten sposob czas produkcji aplikacji wydluzylibysmy tak bardzo, iz bardziej by sie oplacalo nawet dla klienta zewnetrznego dorzucic extra drugi serwer/ram/procesor czy co tam moglo by mu pomoc – wyjdzie to taniej 🙂
każdy orze tak jak może 🙂 ja uważam, że warto się zastanowić czy to co zrobiliśmy jest dobre. tak samo uważam, że warto pisać testy. oczywiście wszystko z umiarem – nie chodzi o to żeby nad każdym selectem siedzieć 2 dni. drugi serwer/ram/procesor nie zawsze jest możliwy a i nie zawsze pomoże.
wiem, że można coś dostarczyć albo szybko albo dobrze – ja wybieram coś pośrodku
Ja też się kompletnie nie zgadzam z Twoją opinią. Zapominając o indeksach czy nie używając istniejących ( na przykład poprzez konwersję typów, stosowanie funkcji w where) można bardo łatwo zarżnąć każdą bazę danych.
No cóż. Najprostszy błąd projektowy jaki można popełnić i bardzo bolesny w skutkach. Ale takie kwiatki łatwo wyłapać, nie da się przecież nawet FK założyć w przypadku niespójnych typów danych.
Zamiast budować protezy typu ProductIdTranslations ja bym refaktoryzował bazę, co od jakiegoś czasu staje się wykonalne nawet w większych projektach z narzędziami typu SSDT..
jak masz 20-letni system to ciężko jest przeprowadzić dużą refaktoryzację. nie przez brak narzędzi a ryzyko wprowadzenia zbyt wielu zmian.
zmiany można wprowadzać małymi krokami i wtedy taka tabelka pomaga.
Fajny artykul no i ciekawy Tool 🙂
Jakim Frameworkiem poslugujecie sie, zeby mapowac te dane w kodzie?
Jak ten programista “sprytnie” ominal problem roznych typow string/int w kodzie w mapowaniu? 🙂
Optymalizacja ogolnie w porzadku, ale w kodzie zrodlowym bedzie troche dodatkowego kodzenia…
Wydaje mi sie, ze latwiej rozszerzyc tabele Products o pole ID typu int,
niz tworzyc nowa tabele “translations”.
Zapytanie bedzie latwiejsze i struktura prostrza, no i prosciej bedzie rozszerzyc mapowanie w kodzie.
– zmienic nazwe pola Product ID na pole Product IDChar i ustawic jako Unique .
– dodac nowe pole Product ID int.
– klucze obce aktualizowac na nowe pole Product ID int.
Ogolnie ile tam masz danych w tych tableach?
Bo czas(Duration) bardzo maly masz. Widac nie duzo jest tego.
Baza danych MSSQL na licencji Enterprise dla duzej ilosci danych, ladnie potrafi optymalizowac zapytania z uzyciem rownoleglego przeszukiwania indeksow dla danego zapytania, jesli zrobic Partitioning dla indexu, np. po dacie, lub GUID itd..
Ale dla sklepu to licencja Express juz wystarczajaca pewnie 🙂 Bo po co obciazac klienta dodatkowymi kosztami, wiec rozwiazanie jest OK!
to co widać na screenach przygotowałem na potrzeby tego posta
baza w systemie nad którym teraz pracuję ma ok 1TB, największa tabela ma 1 500 000 000 (tak, półtora miliarda) wierszy a większość ważnych tabel ma po 200-300 milionów.
dodatkowa kolumna pomogłaby jakby była tylko jedna tabela z innym typem 🙂
– piszesz: “ale taki twór może się zdarzyć, więc warto się tym zainteresować”
Chodzilo tobie o zaprezentowanie Toola, czy wymyslonego problemu “a gdyby”?
To w takim razie po co analizowales ten przyklad, skoro u ciebie nie wystepuje i pewnie u nikogo, kto uzywa normalnych ORM-ow tez nie wystapi?
– Wiec rozumiem, ze ta duza baza to nie sklepy i produkty?
– nie chodziło o zaprezentowanie toola (wspomniałem o nim dopiero w komentarzu) a realnego problemu, który w bazie może wystąpić i z którym się spotkałem
– nigdzie nie wspominam o ORMie
– nie wiem jaki związek mają sklepy i produkty z wielkością bazy ale pokazany tutaj przykład stworzyłem na potrzeby posta.
OK, w takim razie nie rozumiem tego posta.
90% czasu zajelo mi zrozumienie, jak ktos potrafil tak namieszac w bazie.
No ale skoro robi sie cos niezgodnie z zasadami, no to niestety poprawianie tego zajmuje duzo oczasu i trzeba oblozyc sie roznymi pomocnymi Toolami.
Co do wielkosci baz, to juz nie musiales pisac, ze baza w systemie nad którym pracujesz ma tyle dancyh, bo ze pracujesz nie znaczy ze ja tworzysz i optymalizujesz i zarzadzasz. Wiec troche tutaj probujesz sie przechwalac.
Pewnie kilka osob czytajacych tego posta, pracuje nad podobnie duzymi lub wiekszymi systemami.
Ogolnie tez pracuje, tworze i zarzadzam systemem i jego baza, ktora ma 1mld danch per jedne maly kraj, a Panstw jest obecnie 20.
I nikt by sobie nie pozwolil na taki blad. Uwazam, ze przyklad jest nieudany, bo zamiast pomagac, robi zamet.
piszesz:
“Dzisiaj chciałbym zwrócić Waszą uwagę na pilnowanie typów danych w MS SQLu (i w innych silnikach bazodanowych pewnie też).
Czasami przez nieuwagę możemy nieźle namieszać na bazie i nawet początkowo o tym nie wiedzieć.”
No niewiedziec to moga o tym studenci na przyklad…ale od tego jest w pracy zawsze osoba, ktora ja pilnuje i do takich bledow nie dopuszcza.
Co do “i w innych silnikach bazodanowych pewnie też” – jak nie jestes pewny czy tez tak jest, to nie pisz, ze pewnie tez… W relacyjnych bazach danych, to pewnie tez..w NoSQL pewnie nie, itd.. mozna wymieniac.
Ogolnie to fajnie, gdybys dopisal jaka to baza, ktora testowales.
To na tyle.
Ale znalazles fajny sposob, zeby zachecic do czytania twojego bloga.
dzięki, za komentarze – w końcu jakieś ożywienie na blogu 🙂
odnośnie tego co napisałeś:
niczym się nie przechwalam. jakbym tą bazę projektował to bym napisał, że ją projektowałem. nie wiem jak inaczej napisać, że w projekcie jest taka baza. zapytałeś ile jest danych w bazie to odpowiedziałem.
“90% czasu zajelo mi zrozumienie, jak ktos potrafil tak namieszac w bazie.”
my (jako zespół, który w projekcie pracuje – żeby nie było, że znowu się przechwalam 😉 ) do dzisiaj tego nie rozumiemy
“No niewiedziec to moga o tym studenci na przyklad…”
też tak kiedyś myślałem ale życie inaczej to weryfikuje. “kwiatki w kodzie” sadzą nie tylko studenci.
“Ale znalazles fajny sposob, zeby zachecic do czytania twojego bloga.”
bardzo mnie to cieszy 🙂
Comments are closed.